Working with heritage images is hugely rewarding. Not only is it a pleasure to play a part in releasing images of beautiful and interesting artworks and museum objects to the public, but also, there are interesting challenges not faced in other sectors. Heritage images need data fields to describe both the object or artwork depicted, and the image of that object; the organisations producing and distribiuting these digital images need a workflow that encompasses public access and commercial uses of the image, and the needs of the very different departments through which an object and its image pass.
Objects are looked after by curatorial departments, and the data about them is stored in collections management systems. They are photographed by freelancers or photography departments and the images are passed to cataloguing departments, for use on the web site, for educational use, and for commercial sales in the picture library. For historical reasons, most workflows haven't yet been joined up, and that's another challenge we face with the data.
Metadata is the driver for images as they pass through the workflow. Without an identifying number, for example, an image cannot be processed using current systems and may as well be thrown into the digital equivalent of a super sewer.
There are two sets of people thinking about how pictures are transferred from one place to another - what we call interoperability - and they fall mainly into two groups. There are the picture professionals who create images and handle them on their way to publication, and there are the cataloguers and library professionals who handle much of the specialist data about the objects depicted in the images.
The way metadata is exchanged is reflected in the make up of these groups. Library and museum professionals are increasingly looking at schemas like LIDO (which comes from the museums community) which is based on XML, is event based, machine readable, granular, and can hold a deep level of complexity. LIDO is an exciting development for data exchange, but that information is not accessible to people looking at an image which has escaped from its database environment. It is not embedded in the image.
Understanding XML is something of an IT or library skill. Every XML schema has its own set of rules, and to work with the data, or to make it human readable, you need to use an XSLT transformation file which is a template for handling the XML data. Data expressed in XML is not very accessible to those who are not used to it.
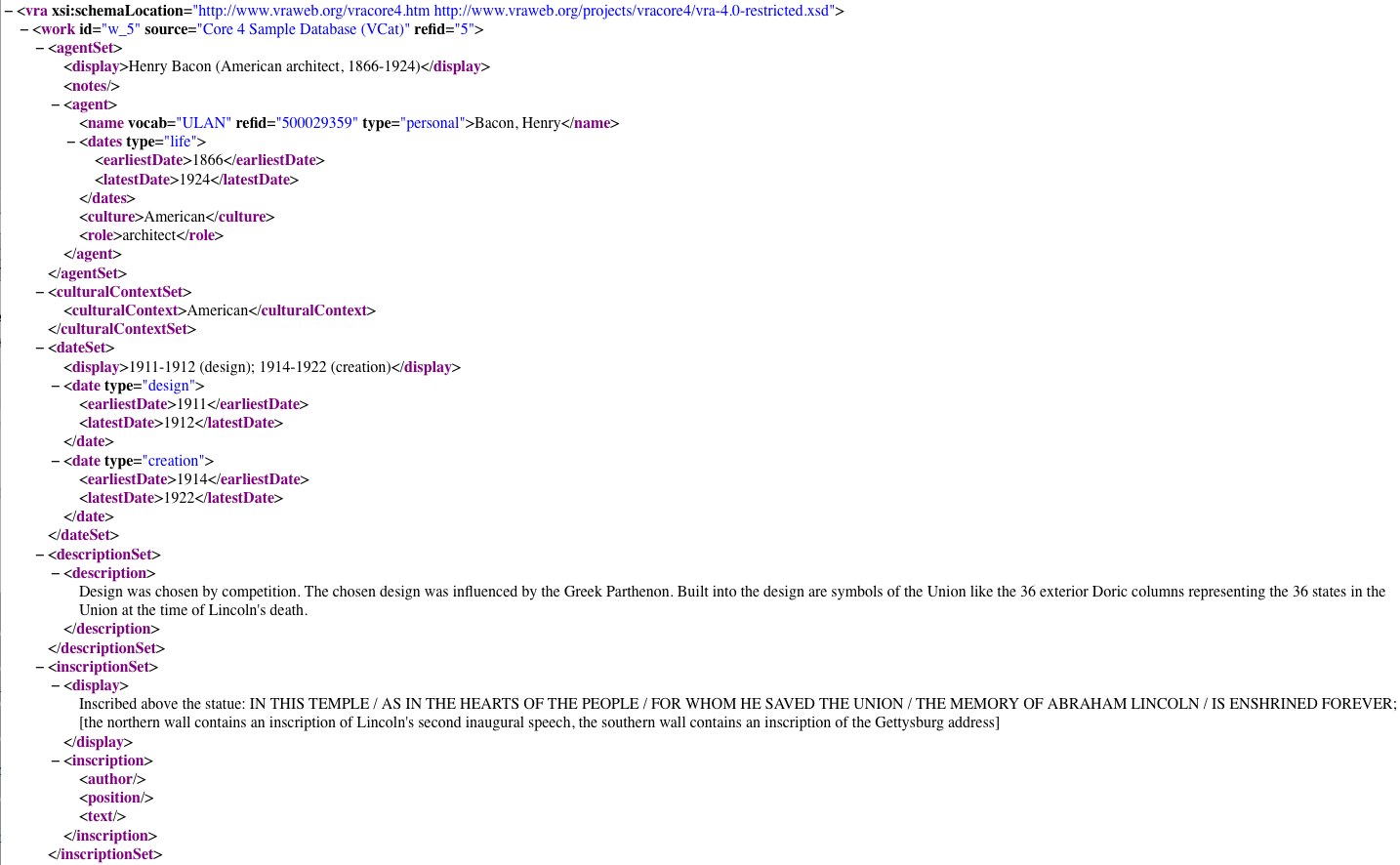
Below is a user-friendly display of some data in the VRA Core schema and its corresponding XML.

For embedded image metadata to be truly useful it must be readable by commonly used media software. Two things are necessary to make this possible: agreed upon technical standards for reading and writing the metadata and agreed upon schemas for giving it structure and meaning. The technical standards have evolved to the customizable, open-source Adobe XMP standard. Because XMP uses extensible RDF/XML standard, it allows the use of rich metadata schemas such as IPTC, the most widely used schema for describing the content and intellectual property rights of an image. The reliable portability of XMP means all IPTC fields can be read by Photoshop and Bridge and other media handling software, and the most essential of the fields can be accessed by anyone, using their computer's file browser (see Screengrab 1 below)
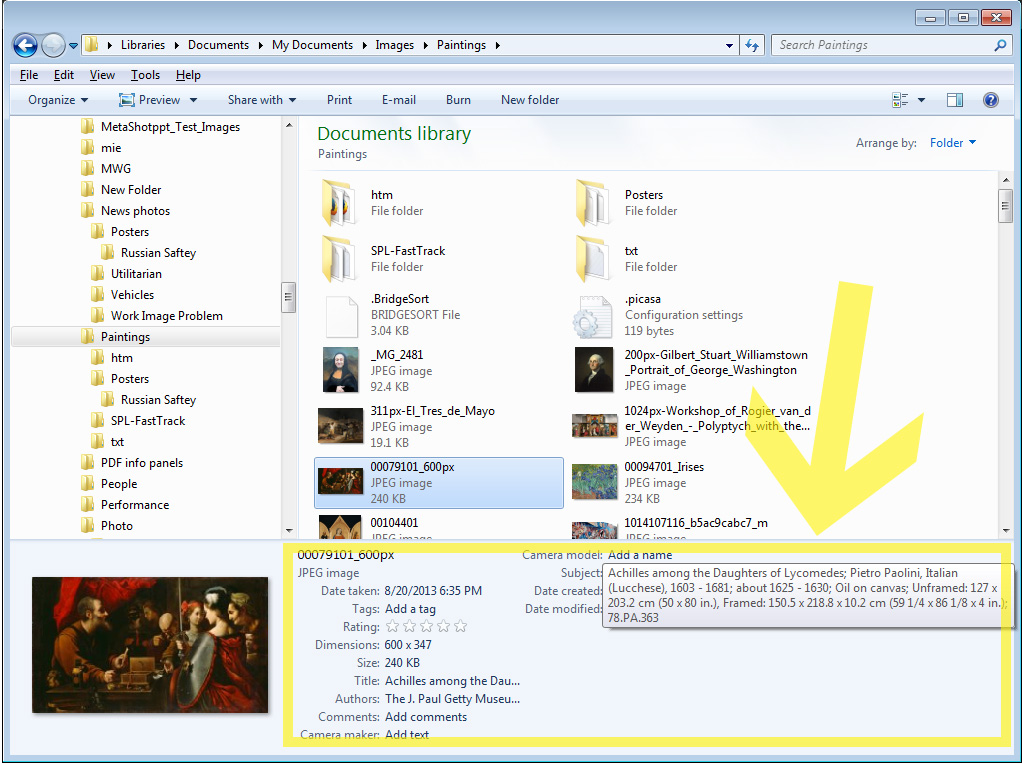
Screengrab 1
Data which is embedded is attached to the image file, and that is a distinct advantage in a number of situations. The IPTC Extension schema has fields to describe artworks and objects in the image, and the IPTC is considering adding some additional key fields for general heritage use (eg. circa date) .
For data exchange within and between museums and galleries Greg Reser (Chair of the VRA Embedded Metadata Group) and I are proposing a richer set of data fields called SCREM to describe the image and the artwork in a more specialist context.
Here are some examples of how embedded metadata can be used.
The Photographer
The photographer of an artwork embeds the inventory number into the image, which is passed on to the curators and cataloguers for further data enrichment. They may also embed the photographer's name, the job number, the name of the artist and other details available at this stage eg the inscription on the back of an artwork. The inventory number is picked up by the cataloguing software, or it can be exported by the photographer into a spreadsheet along with the (hopefully unique) filename. But the inventory number is not separated from the image file whatever happens to the spreadsheet, and the image is uniquely linked to the object.
Data entered in IPTC Core and Extension. SCREM will add useful fields.
The Teacher
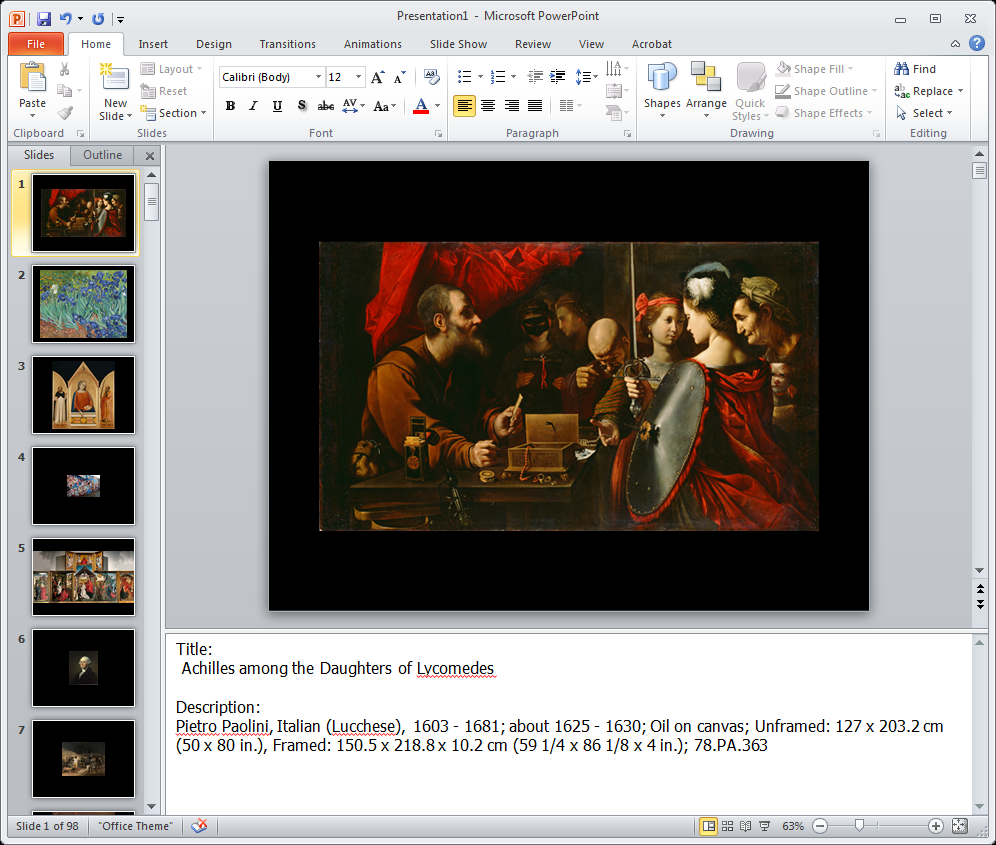
The collections management team embeds key information about the artist, the artwork, and the artwork rights in images sent for for upload to the museum web site. A teacher looks at images on the museum site and, using right-click, downloads an image onto the desktop. The key data about the artist, the artwork, the museum, the dates, the material and size of the painting are embedded in the image. Much of this data can be viewed in the teachers file browser (eg Windows Explorer) and used for teaching. The teacher may also decide to use a utility which reveals the data in the notes section of Powerpoint for use in lectures. (see Screengrab 2 )
Data entered in IPTC Core and Extension.
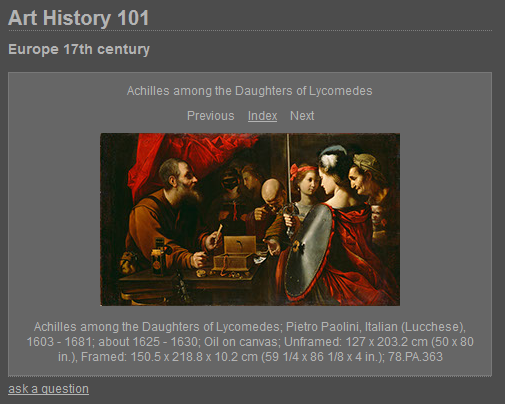
....or might want to display the information in online notes for students(Screengrab 3)
Museums Loans
A museum receives images of artworks loaned by another museum for a special exhibition. The images are to be used in the catalogue and on the web site. Sometimes IPTC data is included in the image files. This is useful as it can be imported into the museum DAM system, but IPTC Extension isn't as extensive as the museum may like and so some fields have to be jammed together into one and then separated after ingest into the DAM. This is not ideal and these users would love to have a way of receiving a richer set of embedded data in a standard way.
Data entered in IPTC Core and Extension. SCREM will allow for more granular specialist data exchange.
Embedded data can play an important and practical role in data exchange. It can be read by people using commonly available image management software and some fields can be read by anyone with a computer. What's not to like ?
We don’t see this as an either or between embedded or non-embedded methods of data exchange; data management is developing all the time. But people working now are finding uses for heritage data embedded in the image file, and we are proposing a sub-set of existing fields (not to reinvent the wheel) which can be carried in the image file and supported by a custom XMP panel, so data entered by one party is read at the receiving end in the same way.
The IPTC expanded set of heritage fields will include those commonly needed by general users for describing and identifying the artwork. The SCREM set of fields will be richer, and will be useful for imaging and cataloguing professionals in heritage organisations. SCREM can be associated with a custom XMP panel which makes the data easily visible in Bridge or Photoshop.
We have issued a survey Expanding Cultural Heritage Metadata to gain feedback on our approach to this. Do take part!
With thanks to Greg Reser a metadata expert and Chair of the VRA (Visual Resources Association) Embedded Metadata Group. . We are working together to improve life for people working with heritage data.